
Language and Data Challenges
Written language has evolved from primitive cave paintings to the digital files that power today’s information age, serving as a foundational technology for recording and sharing knowledge. In the era of data-driven decision-making, technologists face a critical challenge: most documents are unstructured, making it difficult to extract actionable insights efficiently. Structuring document data is essential for leveraging it in analytics, automation, and decision support. This blog explores how raw, unstructured data can be transformed into structured, usable formats using advanced tools-particularly AI agents and document intelligence platforms such as Azure and Databricks-to enhance human interaction with unstructured information.
What will you learn in this blog post?
-
The nature and complexity of unstructured documents
-
The limitations of traditional OCR and the importance of understanding document relationships
-
How GPT and large language models (LLMs) revolutionize document processing
-
The rise of agentic workflows and autonomous AI agents in document intelligence
-
Real-world application examples and best practices for structuring document data
Defining the Document Problem
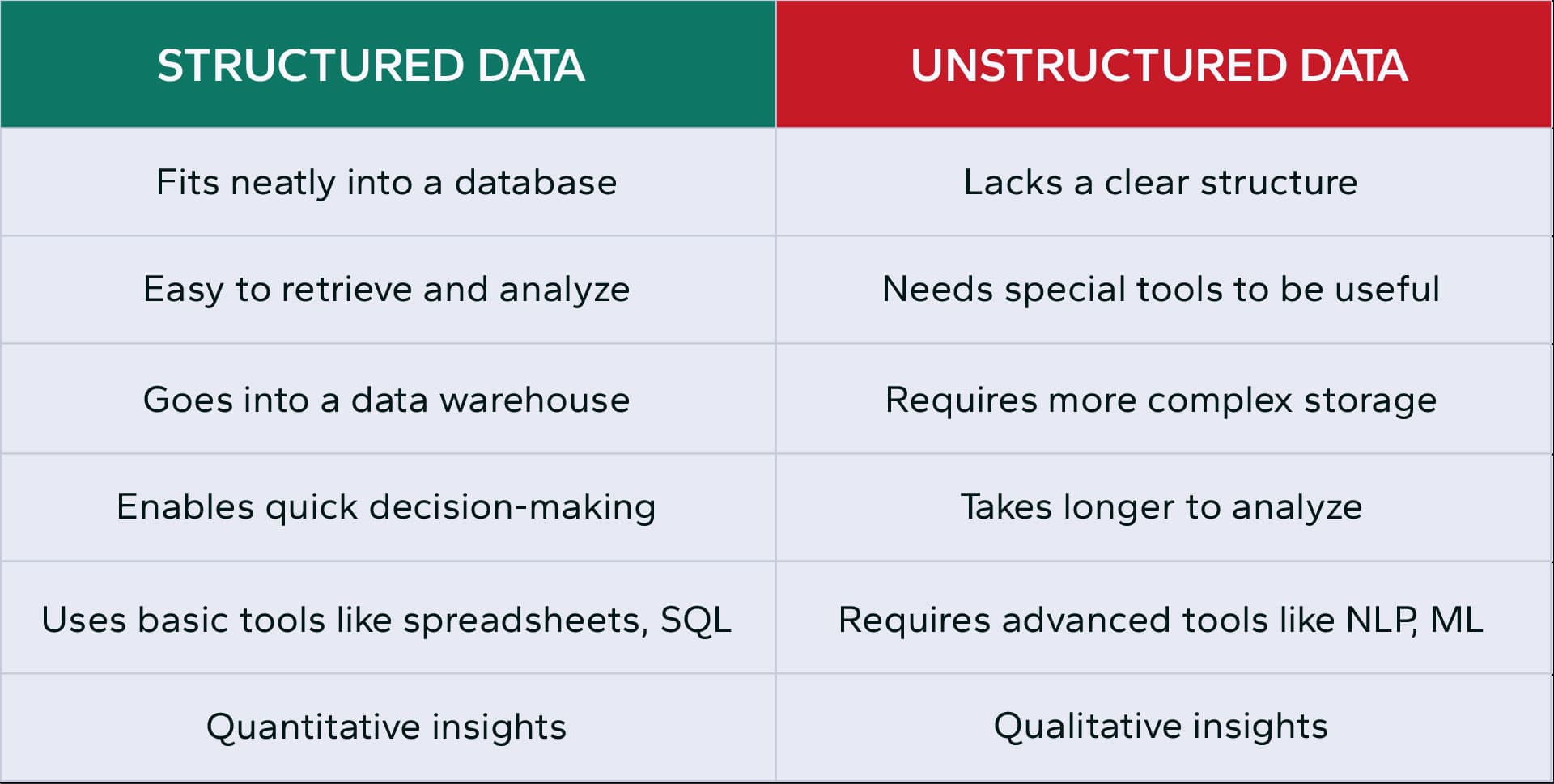
Documents come in many forms-some are simple, while others span hundreds of pages and contain complex tables, charts, and mixed content types. This variability means documents are often considered unstructured data: they lack a consistent, machine-readable format, making them difficult to process with traditional tools5. Technologies like Optical Character Recognition (OCR) can convert images and scanned pages into text and sometimes identify tables, but they struggle with the diverse structures and layouts found in real-world documents. As a result, extracting meaningful information from such documents remains a significant challenge.
Limitations of OCR and the Importance of Document Relationships
While OCR is a crucial first step in digitizing documents, it has notable limitations. OCR can introduce errors, especially with poor image quality or handwritten text, and it often fails to recognize the semantic structure of documents-such as page breaks, nested tables, or the relationships between sections. The real value of documents often lies in their relationships to one another. For instance, a contract may reference amendments, purchase orders, and invoices, forming vertical and horizontal hierarchies that are essential for a complete understanding of business processes. Recognizing and modeling these relationships is vital for holistic document intelligence.
Examples of Document Hierarchies
Document hierarchies are common in many industries:
-
Research & Development: A research paper may lead to follow-up studies, patent filings, and product documentation, each citing or building upon the previous work.
-
Supply Chain: Bills of lading, certificates of insurance, shipping receipts, and claims are interconnected, with each document type playing a role in the broader workflow.
Understanding both the vertical (sequential) and horizontal (cross-type) relationships between documents is crucial for accurate data extraction and process automation810.
GPT Models as a Breakthrough
Generative Pre-trained Transformers (GPT) represent a major leap forward in document intelligence. These foundation models are trained on massive datasets and use transformer architectures to understand and generate language with remarkable accuracy and nuance. GPT models can handle the vast parameter space of human language-encompassing vocabulary, grammar, and context-making them ideal for processing unstructured documents that mix text, numbers, and tables.
Generative Pre-trained Transformers Explained
GPT models work by embedding language into high-dimensional mathematical spaces, allowing them to capture complex relationships between words, sentences, and document sections. Through mechanisms like attention and normalization, transformers can focus on relevant parts of the input and generate coherent, context-aware outputs. This enables them to perform tasks such as summarization, entity extraction, and document classification with minimal manual intervention.
The Expansion of Data in Document Processing
Processing a document isn’t just about reducing it to key data points. In fact, the workflow often involves expanding the data: OCR might turn a thousand-word document into millions of data points, which are then further processed by NLP and LLMs. This expansion is necessary to capture all possible relationships and context, ultimately allowing the system to contract back to a concise, structured data model that highlights the most critical information.
Agentic Workflows and AI Agents
Modern document intelligence leverages agentic workflows-modular, autonomous agents that specialize in different tasks:
-
Inspection Agent: Deeply analyzes files for structure and content.
-
OCR Agent: Converts images and scanned documents into text.
-
Vectorized Agent: Chunks documents into tokens for LLM processing.
-
Splitter Agent: Determines logical document splits.
-
Extract Agent: Identifies and extracts key data points.
-
Matching Agent: Maps relationships across document hierarchies.
These agents work together to automate and optimize the entire document processing pipeline, reducing manual effort and increasing accuracy.
Autonomous Agentic Workflows
Unlike traditional, linear data pipelines, agentic workflows can be event-driven and highly autonomous. Agents can trigger each other, collaborate, and even make decisions based on intermediate results. This architecture enables greater efficiency, scalability, and adaptability-opening up new possibilities for document-centric automation and knowledge work.
Application Example: Intelligent Document Processing in Finance
A major financial institution processes thousands of loan documents, contracts, and statements every month. By implementing an agentic workflow powered by Databricks and Azure AI, the organization automates OCR, classifies document types, extracts key financial data, and maps relationships between contracts and amendments. LLMs like GPT-4 analyze the extracted data, summarize findings, and flag anomalies for human review. This results in faster turnaround times, reduced errors, and improved compliance.
Important Points to Remember
-
Most enterprise data is unstructured, residing in documents that are difficult to process without advanced tools.
-
OCR is essential but limited; true document intelligence requires understanding relationships and context.
-
GPT and LLMs enable high-accuracy extraction, classification, and summarization of complex documents.
-
Agentic workflows, orchestrated by AI agents, automate and optimize document processing, making it scalable and adaptive.
-
Platforms like Databricks and Azure offer robust infrastructure for building, training, and deploying these intelligent document processing solutions.
In summary
Transforming unstructured document data into structured, actionable insights is now feasible thanks to advances in AI, LLMs, and agentic workflows. By embracing these technologies, organizations can automate knowledge work, improve decision-making, and unlock the full value of their document assets.



